Un buen test de integracion no busca repetir lo que ya cubren las unitarias, sino comprobar que piezas distintas del sistema encajan de verdad: API, base de datos, colas, autenticación, servicios externos y, cada vez más, componentes de IA. En este artículo explico qué valida, cómo diseñarlo sin convertirlo en una suite lenta y qué cambia cuando el flujo incluye modelos generativos, RAG o herramientas externas. También verás errores comunes, cómo priorizar casos y cómo meter estas pruebas en CI/CD sin frenar al equipo.
Las pruebas de integración detectan fallos de contrato y de orquestación antes de producción
- Sirven para verificar que dos o más componentes funcionan juntos como se espera.
- Son más amplias que una unitaria, pero mucho más rápidas y baratas que un flujo extremo a extremo completo.
- En sistemas con IA, validan también prompts, recuperación de contexto, herramientas externas y formato de salida.
- Su valor real aparece cuando prueban el flujo que más riesgo tiene para negocio, datos o experiencia de usuario.
- Si se vuelven lentas o frágiles, dejan de ayudar y pasan a estorbar al equipo.
Qué problema resuelve una prueba de integración
La diferencia importante no es académica, es operativa. Microsoft Learn lo resume bien: una prueba de integración verifica que dos o más componentes funcionen juntos. En un producto real eso significa descubrir fallos que no aparecen en una función aislada, como un cambio de esquema en la base de datos, un token mal propagado, una cola saturada o una respuesta de un servicio externo que ya no encaja con lo que esperabas.
Yo suelo pensar en este tipo de prueba como la capa que responde a una pregunta muy concreta: ¿el sistema sigue funcionando cuando las piezas se conectan? Si la respuesta importa para negocio, merece una prueba; si no, probablemente estás gastando tiempo en un caso que debería vivir en otra capa. Esa distinción ayuda mucho cuando el equipo tiene prisa y la tentación es probar “todo” en el mismo sitio.
En productos con IA, la pregunta se amplía: no solo importa que el modelo responda, sino que el contexto llegue bien, que la salida se pueda consumir y que las herramientas asociadas hagan lo correcto. Esa transición nos lleva a comparar esta capa con las demás para no mezclar responsabilidades.
Cómo se diferencia de una unitaria y de extremo a extremo
| Tipo de prueba | Qué valida | Velocidad | Cuándo aporta más valor |
|---|---|---|---|
| Unitaria | Una función, clase o regla aislada | Muy alta | Lógica, cálculos, validaciones y bordes internos |
| Integración | Dos o más componentes trabajando juntos | Alta o media | Contratos, persistencia, APIs, colas y dependencias reales |
| Extremo a extremo | El flujo completo del usuario | Más baja | Escenarios críticos de negocio o UX |
La regla práctica que más me sirve es esta: cuanto más cerca estás del comportamiento interno, más barata y estable suele ser la prueba; cuanto más cerca estás del usuario final, más confianza ganas, pero también más coste y fragilidad asumes. Por eso una suite sana no intenta resolverlo todo con una sola capa. La siguiente pregunta lógica es qué piezas concretas merecen entrar en la prueba cuando hay IA en medio.
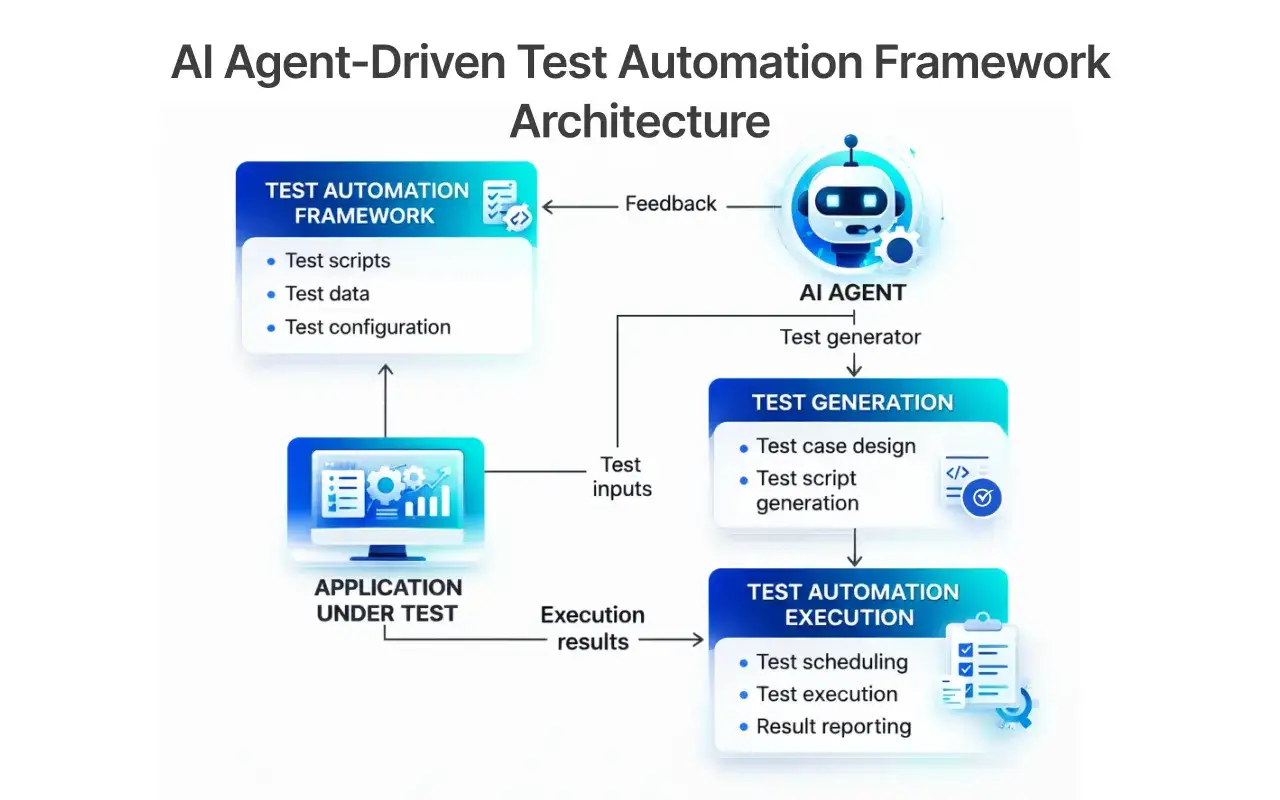
Qué partes conviene validar en una arquitectura con IA
Cuando el sistema incorpora IA, la integración deja de ser solo “servicio A llama a servicio B”. Ahora también hay que vigilar el prompt, la recuperación de contexto, el orquestador, los permisos y el formato final de la respuesta. En un flujo de RAG, por ejemplo, RAG significa recuperación aumentada por generación: primero buscas contexto relevante y luego el modelo genera la respuesta con ese apoyo. Si ese paso intermedio falla, el resultado puede parecer correcto y aun así estar mal fundamentado.
| Componente | Qué compruebo | Fallo típico |
|---|---|---|
| Entrada del usuario | Campos obligatorios, tipos, longitud y codificación | Datos mal normalizados o incompletos |
| Prompt o instrucción | Contexto, variables y reglas de salida | Instrucciones ambiguas o demasiado largas |
| Recuperación de contexto | Que se traigan los documentos correctos | Vectores irrelevantes, filtros erróneos o latencia alta |
| Herramientas externas | Llamadas a APIs, bases de datos y colas | Timeouts, reintentos excesivos o permisos insuficientes |
| Salida final | Esquema, trazabilidad y consumo por otro sistema | JSON roto, formato inconsistente o respuestas no accionables |
En la práctica, yo no probaría todos los componentes con la misma profundidad. Me centro en el tramo que más dinero, soporte o reputación puede romper si falla. Ese criterio de prioridad nos lleva al diseño paso a paso.
Cómo diseñarla paso a paso sin volverla frágil
Lo que mejor funciona no es crear una gran suite genérica, sino elegir un flujo importante y protegerlo bien. Cuando el equipo intenta cubrir demasiados casos a la vez, la prueba se vuelve lenta, difícil de leer y muy sensible a cambios menores.
- Elige un flujo crítico. Por ejemplo, registro de usuario, compra, búsqueda documental o generación de un informe con IA.
- Define el contrato. Especifica qué entra, qué sale y qué no puede cambiar sin romper la prueba.
- Aísla solo lo inestable. Si un servicio externo cambia cada semana, usa un doble de prueba, es decir, un sustituto controlado que devuelve respuestas previsibles.
- Prepara datos representativos. La prueba debe parecerse al uso real, no a un caso perfecto inventado en el vacío.
- Comprueba el resultado de negocio. No te limites a verificar llamadas internas; valida el efecto final que le importa al usuario o al sistema siguiente.
- Deja limpia la huella. Si la prueba escribe en base de datos, cola o almacenamiento, debe deshacer lo que crea o trabajar en un entorno efímero.
Yo suelo fijar un objetivo operativo sencillo: si preparar o ejecutar una prueba empieza a costar más de 2 o 3 minutos de forma habitual, ya toca simplificarla o dividirla. La siguiente capa de calidad no está en hacerla más grande, sino en evitar los errores que la vuelven poco fiable.
Los errores que hacen que una suite pierda valor
- Probar demasiado lejos del punto de integración. Si todo está mockeado, acabas validando tu código contra tus propias suposiciones.
- Depender de datos globales. Una base compartida o un entorno sucio convierte una buena prueba en una lotería.
- Asentar la prueba en detalles internos. Si cambias una implementación sin cambiar el comportamiento, la prueba no debería romperse.
- No controlar tiempo, fecha o aleatoriedad. En flujos con IA esto es todavía más importante, porque la variación se multiplica.
- Ignorar los casos negativos. Un flujo integrado también debe fallar bien cuando falta un permiso, una API cae o el contexto llega vacío.
- Dejar pasar la flakiness. Si una prueba falla y luego pasa sin tocar el código, no es “ruido”: es deuda técnica real.
Lo curioso es que casi todos estos problemas aparecen cuando la suite crece sin una estrategia clara. Por eso la integración no debería vivir aislada, sino dentro de un pipeline que proteja el tiempo del equipo.
Cómo encajarla en CI/CD sin frenar la productividad
En equipos de IT, la prueba de integración funciona mejor cuando entra en una cadena de validación por capas. Yo suelo separar tres ritmos: una vía rápida para cambios frecuentes, una capa principal para los flujos críticos y una ejecución más pesada para la noche o para antes de una liberación importante.
| Capa | Qué incluye | Objetivo práctico |
|---|---|---|
| Fast lane | Unitarias, contratos básicos y un puñado de integraciones clave | Dar feedback en minutos tras cada pull request |
| Main lane | Integraciones críticas del producto | Bloquear defectos serios antes de mergear |
| Nightly | Escenarios más caros, flujos largos y casos con IA más variables | Detectar regresiones sin penalizar cada cambio |
Mi criterio es bastante simple: si una suite clave supera los 15 minutos de forma constante, ya no está ayudando al equipo como debería. No hace falta esperar a que llegue a media hora para dividirla. También me gusta mantener los fallos intermitentes fuera de la vía principal hasta que estén corregidos, porque un pipeline ruidoso termina perdiendo credibilidad.
Este enfoque encaja muy bien con equipos que buscan eficiencia, porque reduce el tiempo perdido en falsos positivos y evita que desarrollo, QA y producto se bloqueen unos a otros. A partir de ahí, el matiz importante está en cómo evaluar sistemas con IA generativa, donde el comportamiento no siempre es determinista.
Qué cambia cuando hay modelos generativos de por medio
La diferencia esencial es que una respuesta de IA no siempre será idéntica aunque la entrada sea la misma. La guía de evaluación de OpenAI insiste precisamente en esa variabilidad: si la salida cambia, una comparación literal deja de ser suficiente. Por eso, en este tipo de integración me interesa más el comportamiento que la frase exacta.
En la práctica, eso significa combinar varias formas de comprobación:
- Validar el esquema de salida, por ejemplo JSON válido y campos obligatorios presentes.
- Comprobar que el modelo ha usado el contexto correcto, no solo que “suene bien”.
- Medir si la respuesta cumple un criterio semántico, como resolver la intención del usuario o citar una fuente recuperada.
- Probar fallos reales, como contexto vacío, documento corrupto, tiempo de espera agotado o herramienta externa caída.
- Fijar versión de modelo, temperatura y parámetros de llamada para reducir ruido en entornos de prueba.
Yo aquí soy bastante estricto: si el sistema depende de una IA para una decisión operativa, no basta con ver que “contesta algo razonable”. Tiene que integrarse bien con el resto del flujo, dejar trazabilidad y fallar con elegancia cuando algo sale mal. Esa disciplina es la que evita sorpresas en producción.
La regla práctica que uso antes de ampliar la cobertura
Antes de añadir más casos, me hago tres preguntas muy concretas: qué flujo protege más valor, qué dependencia rompe más veces y qué fallo sería más caro de detectar tarde. Si una prueba no responde a una de esas tres preguntas, normalmente no merece crecer todavía.
- Protege primero el recorrido que más impacto tiene en ingresos, soporte o reputación.
- Añade después los contratos que cambian con más frecuencia entre equipos o servicios.
- Reserva los escenarios más pesados para una ejecución menos frecuente, no para cada commit.
Si tuviera que dejar una idea final, sería esta: una buena capa de integración no intenta impresionar por cantidad, sino por precisión. En sistemas con IA, esa precisión se nota todavía más, porque conecta lógica, datos, servicios y comportamiento variable en un solo punto donde el producto demuestra si de verdad funciona.